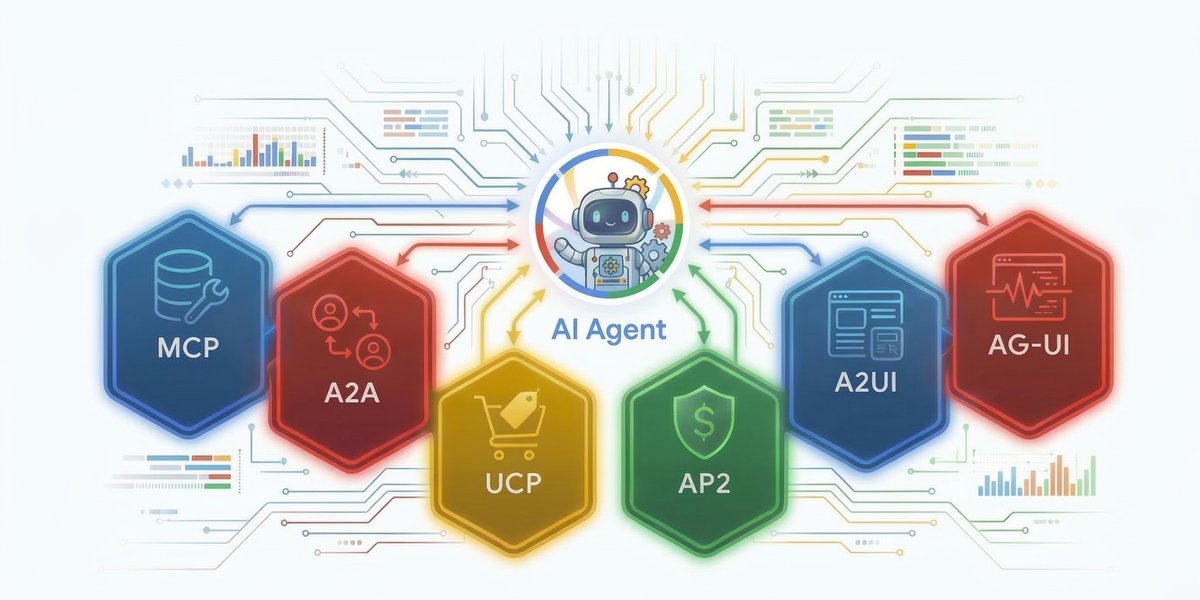
MCP부터 A2A까지, AI 에이전트 표준 프로토콜 가이드
왜 지금 이게 문제인가 LLM을 단순한 챗봇이 아니라 ‘에이전트’로 활용하려는 시도가 늘어나면서 백엔드 엔지니어들은 새로운 형태의 통합 지옥(Integration Hell)에 빠졌다. 기존에는 서비스마다 제각각인 REST API 명세에 맞춰 툴(Tool)을 정의하고, 프롬프트에 수십 개의 함수 명세를 때려 넣는 노가다를 반복해 왔다. 툴 관리의 비대해짐: 에이전트가 처리할 도메인이 넓어질수록 tools[] 리스트는 관리 불가능한 수준으로 길어지고, 이는 곧 컨텍스트 윈도우 낭비와 모델의 추론 성능 저하로 이어진다. 표준의 부재: 서로 다른 팀이나 회사가 만든 에이전트끼리 협업하려면, 결국 또 사람이 개입해서 API 스펙을 맞추고 인증 로직을 새로 짜야 한다. 신뢰와 보안의 트레이드오프: 에이전트에게 실행 권한을 줄수록 보안 리스크는 커지며, 특히 금융권이나 대규모 커머스처럼 ‘무결성’이 중요한 한국 실무 환경에서 ‘Auto-Approve’ 같은 기능은 기술적 부채보다 무서운 운영 리스크가 된다. 구글이 제시한 MCP(Model Context Protocol)와 A2A(Agent-to-Agent) 등의 프로토콜은 이 파편화된 연결 고리를 표준화하겠다는 선언이다. 이제 에이전트는 직접 API를 호출하는 대신, 표준화된 프로토콜을 통해 데이터에 접근하고 다른 에이전트에게 업무를 위임한다. ...