AWS S3 20주년: S3 Tables와 Vectors 등 신기능 및 미래 전망
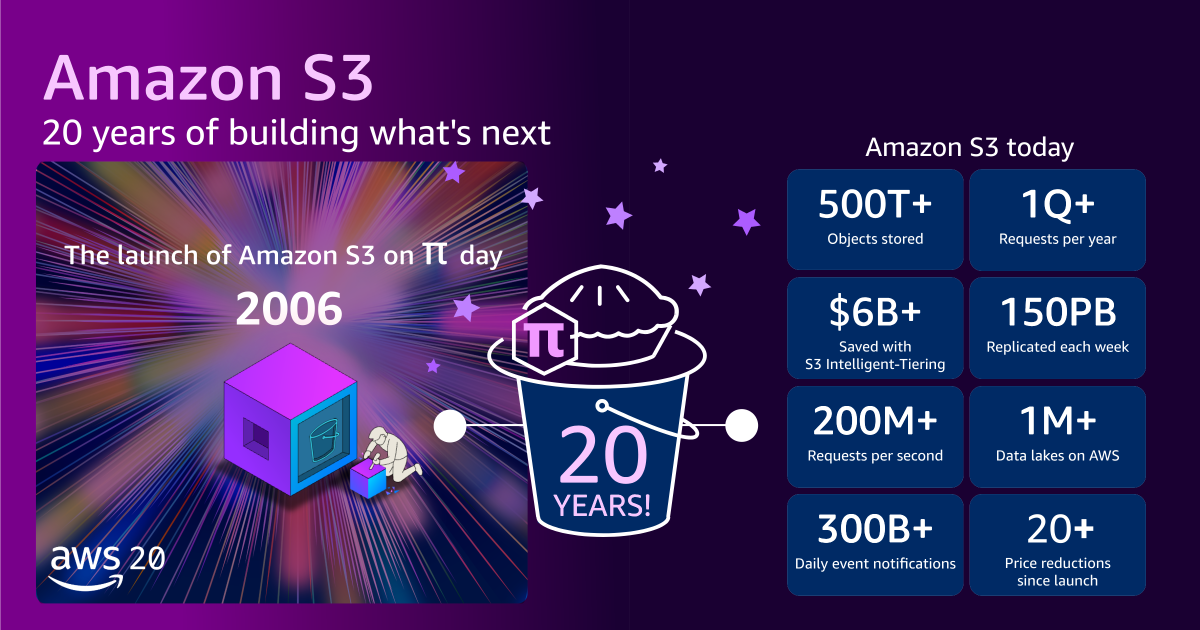
한 줄 요약 — Amazon S3는 20년 동안 API 하위 호환성을 유지하며 단순 저장소에서 AI와 데이터 분석을 위한 통합 플랫폼으로 진화했습니다. 이 주제를 꺼낸 이유 현대적인 클라우드 기반 애플리케이션을 개발하면서 Amazon S3(Simple Storage Service)를 거치지 않기란 불가능에 가깝습니다. 정적 웹 사이트 호스팅부터 대규모 데이터 레이크 구축, 그리고 최근의 생성형 AI를 위한 데이터셋 관리까지 S3는 언제나 그 중심에 있었습니다. 최근 S3 출시 20주년을 맞아 공개된 기술적 회고와 향후 비전은 단순한 기념사를 넘어섭니다. 20년 전 작성한 코드가 수정 없이 여전히 작동한다는 사실은 변동성이 심한 테크 업계에서 경이로운 수준의 신뢰를 보여줍니다. 특히 S3 Tables나 S3 Vectors 같은 신규 기능은 객체 스토리지가 앞으로 어떤 방향으로 확장될지 명확한 힌트를 줍니다. ...
