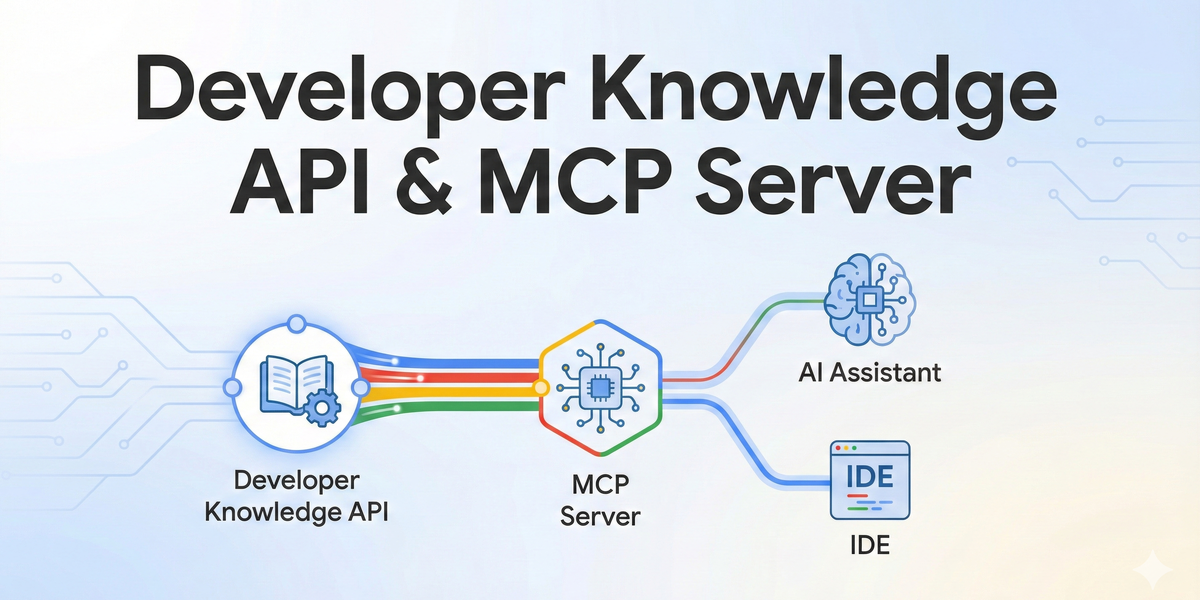
구글 Developer Knowledge API 및 MCP 서버: AI 에이전트 문서 검색 가이드
구글이 제공하는 공식 문서를 AI 에이전트가 실시간으로 검색하고 읽을 수 있게 해주는 Developer Knowledge API와 모델 컨텍스트 프로토콜(Model Context Protocol, MCP) 서버가 공개되었습니다. 이 도구들을 활용하면 AI가 생성하는 코드의 정확도를 높이고, 최신 SDK나 API 변경 사항을 반영하지 못해 발생하는 할루시네이션(Hallucination) 문제를 근본적으로 해결할 수 있습니다. 왜 공식 문서 API가 필요한가? 자바와 코틀린 기반의 백엔드 시스템을 10년 넘게 운영하다 보면 가장 골치 아픈 지점이 바로 라이브러리 버전 업데이트와 그에 따른 문서 파편화입니다. 특히 구글 클라우드(Google Cloud)나 파이어베이스(Firebase)처럼 변화 속도가 빠른 플랫폼을 다룰 때, 구글링으로 찾은 예제 코드가 이미 디프리케이트(Deprecated)된 경우를 수없이 겪었습니다. ...